
Por qué los agentes de IA avanzan más lento de lo esperado
Los agentes de IA no fallan por falta de inteligencia, sino porque ejecutar acciones fiables en un teléfono exige permisos, contexto, confirmación humana y recuperación.
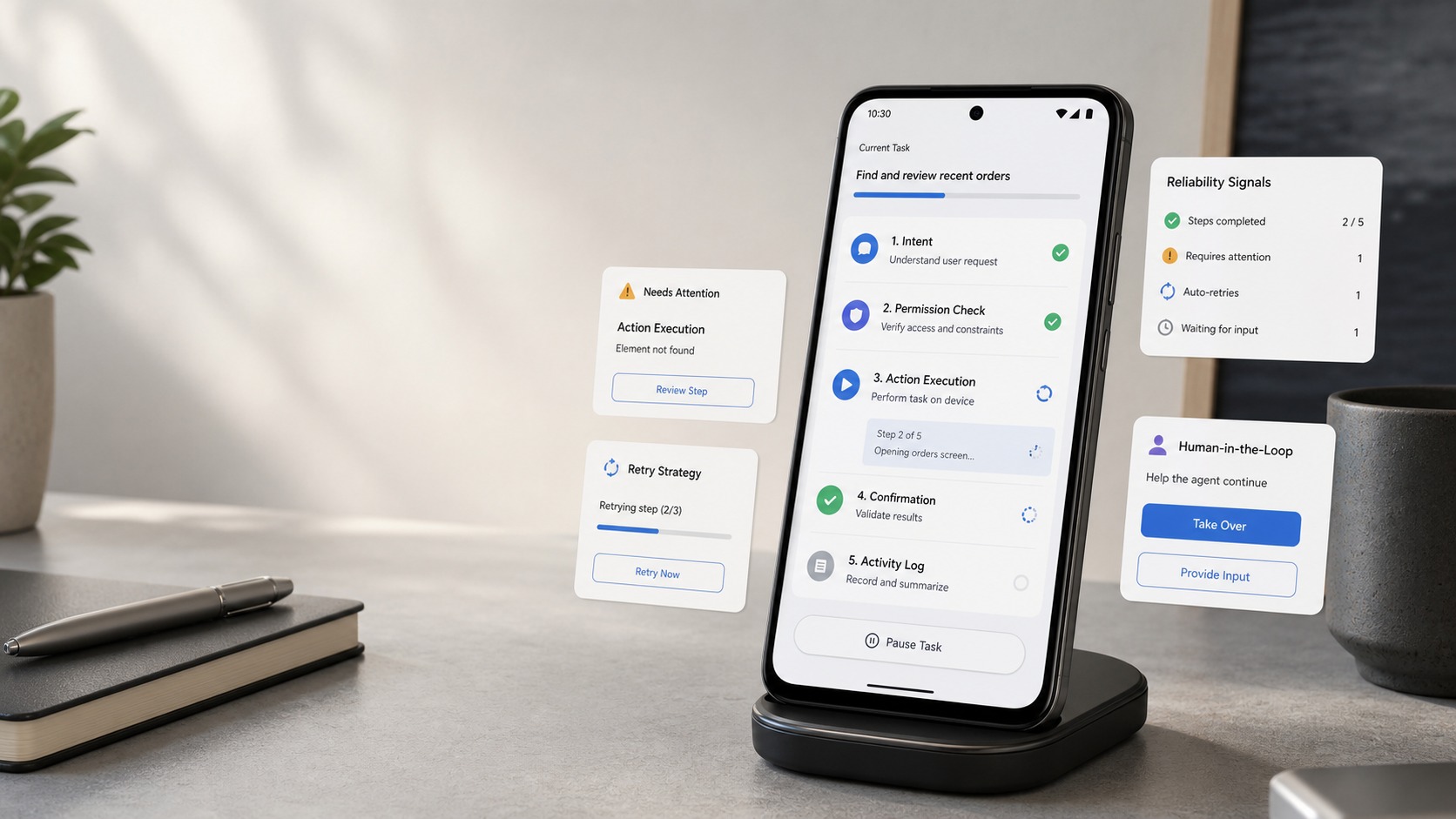
- El avance parece lento porque una demostración brillante no equivale a una acción fiable dentro de aplicaciones reales.
- Un agente de IA para el teléfono necesita una capa de ejecución: permisos claros, interfaces de app, lectura del estado, confirmaciones y rutas de recuperación.
- La confirmación humana no es un freno inútil; es una protección cuando el agente puede enviar mensajes, mover dinero, borrar datos o cambiar ajustes.
- FoneClaw se enfoca en convertir la inteligencia del modelo en tareas telefónicas controlables, auditables y reversibles.
La pregunta de fondo no es si los modelos de IA pueden razonar mejor que antes. Pueden hacerlo. La pregunta útil es por qué los agentes de IA avanzan más lento de lo esperado cuando se les pide actuar por nosotros en un teléfono real. La respuesta corta es que hablar bien, planificar una tarea y tocar una interfaz cambiante son problemas distintos. Un modelo puede entender que quieres reservar una cita, comparar dos opciones o responder un mensaje, pero el salto hacia una acción segura exige comprobar permisos, leer el estado de varias apps, pedir confirmación cuando corresponde y saber qué hacer si algo sale mal.
Por eso conviene separar dos ideas. La primera es la inteligencia del modelo: entender instrucciones, resumir contexto, elegir el siguiente paso. La segunda es la fiabilidad de los agentes de IA cuando deben ejecutar en Android sin romper la intención del usuario. Si quieres una base más amplia sobre qué hace realmente un agente de IA para el teléfono, ese recorrido ayuda a distinguir entre asistente conversacional, automatización y agente con capacidad de acción.
Respuesta rápida
Los agentes parecen ir más despacio porque las tareas valiosas en un móvil son sensibles al contexto. Enviar un correo, confirmar un pago, cambiar una ruta, aceptar un permiso o borrar una foto no son simples pasos de interfaz. Cada acción puede tener consecuencias y cada aplicación expone información de manera diferente. Un agente Android fiable necesita saber qué pantalla está viendo, qué dato falta, qué acción requiere consentimiento y qué estado debe conservar antes de tocar nada.
La diferencia se nota en un ejemplo cotidiano. Pedirle a un chatbot que redacte un mensaje para cancelar una reunión es fácil; pedirle que encuentre la conversación correcta, detecte el tono adecuado, revise si hay archivos adjuntos, espere tu aprobación y envíe el texto por la app correcta es mucho más exigente. El usuario no evalúa al agente por la belleza del plan, sino por si hizo exactamente lo que debía hacer sin exponer datos ni provocar trabajo extra.
Así que el ritmo más lento no demuestra que los agentes hayan fracasado. Indica que el producto real está pasando de la promesa a la ingeniería. En el teléfono, la autonomía útil nace cuando el sistema sabe cuándo actuar, cuándo detenerse y cómo explicar lo que acaba de hacer.
Por qué las demos confunden
Las demostraciones públicas suelen elegir caminos ordenados: una cuenta preparada, una app en buen estado, pocos permisos pendientes y un objetivo claro. Ese entorno muestra potencial, pero no reproduce el desorden de un teléfono personal. En la vida diaria hay notificaciones que interrumpen, sesiones vencidas, botones que cambian de lugar, versiones distintas de una misma app y datos privados mezclados con información laboral.
Un video puede enseñar a un agente completando cinco pasos sin error, pero el producto necesita resolver el sexto paso cuando aparece una ventana inesperada. También debe reconocer si está a punto de comprar el artículo equivocado, responder a la persona incorrecta o compartir una captura con información sensible. Por eso la fiabilidad no se mide solo por si el agente termina una ruta ideal; se mide por su comportamiento cuando la ruta deja de ser ideal.
La conversación sobre Gemini, Android y otros asistentes suele centrarse en la capacidad del modelo, pero el usuario necesita entender la parte operativa. Si sigues la evolución de Gemini 3 y los agentes Android, la lectura práctica es la misma: una demo convincente debe convertirse en control de permisos, acciones verificables y límites visibles antes de delegar tareas importantes.
La capa de ejecución
Un agente de IA para el teléfono necesita una capa de ejecución, no solo una ventana de chat con acceso a la pantalla. Esa capa traduce la intención del usuario en acciones compatibles con aplicaciones reales. Incluye permisos granulares, interfaces de app que permitan llamar funciones de forma estable, lectura del estado actual, validación antes de ejecutar y rutas para deshacer o reparar una acción. Sin esa capa, el agente depende demasiado de observar píxeles, adivinar botones y repetir pasos frágiles.
Las interfaces preparadas para que las apps sean invocables por máquinas son especialmente importantes. Cuando una app ofrece una acción clara, por ejemplo crear un evento, añadir un contacto o cambiar una preferencia, el agente puede pasar parámetros y recibir una respuesta estructurada. En cambio, si solo puede imitar toques sobre una pantalla, cualquier rediseño visual puede romper el flujo. Para profundizar en este requisito, lee cómo las interfaces de apps invocables por máquinas hacen que la ejecución sea menos dependiente de trucos visuales y más fácil de auditar.
La recuperación también pertenece a esta capa. Un agente fiable debe guardar el punto anterior, explicar qué acción intentó, detectar si no recibió confirmación y ofrecer una salida razonable. Si falla al reservar una cita, no debería dejar al usuario con formularios a medias; debería mostrar qué datos se usaron, qué quedó pendiente y qué opción permite continuar manualmente.
Confirmación humana
La confirmación humana no convierte a un agente en menos inteligente. Lo convierte en más apropiado para tareas con riesgo. Hay acciones que pueden ejecutarse sin molestar al usuario, como ordenar una lista, resumir una notificación o preparar un borrador. Otras deben detenerse antes del punto irreversible: enviar dinero, publicar contenido, aceptar condiciones, borrar archivos, cambiar permisos o responder en nombre del usuario.
El diseño correcto no es pedir aprobación para todo. Eso haría que el agente fuera pesado e inútil. El criterio debe depender del impacto, la reversibilidad y la sensibilidad de los datos. Un buen agente puede agrupar pasos de bajo riesgo y reservar la confirmación para el momento que importa: este es el destinatario, este es el importe, esta es la app, esta es la consecuencia. Si no puedes ver ese resumen antes de aceptar, la autonomía está adelantándose a la confianza.
También hacen falta registros comprensibles. Un usuario debería poder revisar qué pidió, qué interpretó el agente, qué acciones completó y cuáles quedaron bloqueadas. Un centro de control para agentes móviles ayuda precisamente porque reúne supervisión, consentimiento y recuperación en un lugar donde la persona mantiene el mando sin tener que leer registros técnicos.
El contexto del teléfono
Un teléfono es más difícil que una conversación porque no es un único documento ni una sola app. Es un entorno vivo con permisos, sensores, cuentas, contactos, archivos, ubicación, notificaciones y rutinas personales. El agente debe interpretar señales incompletas sin asumir demasiado. Una notificación de entrega, un mensaje familiar y una alerta bancaria pueden aparecer juntas, pero no tienen el mismo nivel de privacidad ni requieren la misma respuesta.
Además, Android no es una experiencia uniforme. Hay fabricantes, capas de sistema, versiones de apps, ajustes de accesibilidad y políticas de permisos que cambian la forma de ejecutar una tarea. Un agente puede funcionar bien en un teléfono de prueba y fallar en otro donde la app pide iniciar sesión de nuevo o donde el usuario desactivó una autorización. La fiabilidad exige reconocer esas diferencias y pedir ayuda cuando la automatización ya no tiene suficiente información.
El contexto local también incluye hábitos. Un agente que organiza llamadas debe saber si el usuario prefiere WhatsApp, teléfono, calendario o correo para cada contacto. Pero saberlo no significa invadirlo todo. La parte difícil es usar contexto suficiente para ser útil sin convertir cada tarea en una extracción amplia de datos personales.
Local y nube
La nube puede aportar modelos grandes, mejor razonamiento y actualizaciones rápidas. La ejecución local puede aportar menor latencia, más control sobre datos sensibles y acceso directo a señales del dispositivo. Un agente robusto no debería tratar esta elección como una guerra simple. Algunas tareas se benefician del razonamiento remoto; otras deberían quedarse en el teléfono porque implican contenido privado, permisos delicados o acciones rápidas.
Por ejemplo, comparar opciones de viaje puede aprovechar un modelo en la nube para resumir precios, restricciones y preferencias. En cambio, confirmar qué app abrir, leer una notificación privada o completar un paso dentro de una pantalla sensible puede requerir ejecución local con controles más estrictos. Para ver los matices de esta decisión, la guía sobre compensaciones entre agente en la nube y agente local explica por qué privacidad, latencia y capacidad no siempre apuntan en la misma dirección.
La arquitectura más razonable suele ser híbrida. El agente puede usar la nube para pensar cuando el usuario lo permite y usar componentes locales para observar, ejecutar y proteger datos. Lo importante es que el usuario entienda qué parte ocurre dónde. Si una app promete automatización sin explicar el flujo de datos, la confianza queda apoyada en marketing, no en control real.
Qué deberían esperar los usuarios
Antes de confiar una tarea importante a un agente, conviene evaluar criterios concretos. Primero, el agente debe mostrar qué entendió y qué va a hacer. Segundo, debe distinguir entre preparar una acción y ejecutarla. Tercero, debe pedir confirmación en los puntos de riesgo. Cuarto, debe poder detenerse sin dejar la tarea en un estado confuso. Quinto, debe ofrecer un registro legible de lo que hizo.
Una señal positiva es que el agente admita límites. Si necesita una app compatible, un permiso concreto o una confirmación manual, debería decirlo sin fingir autonomía total. La confianza aumenta cuando el producto no intenta parecer mágico. Un agente que explica por qué no puede completar una tarea suele ser más útil que uno que avanza a ciegas y obliga al usuario a reparar el resultado.
También importa el tipo de tarea. Delegar la organización de borradores, recordatorios, búsquedas o clasificación de mensajes es distinto de delegar compras, pagos, cambios de cuenta o respuestas sensibles. La adopción real probablemente crecerá desde tareas reversibles hacia acciones de mayor impacto, a medida que permisos, controles y recuperación maduren.
Qué significa para FoneClaw
Para FoneClaw, la lección no es prometer que un agente hará todo de inmediato. La lección es construir un puente entre intención y ejecución que respete el teléfono del usuario. Eso implica trabajar alrededor de permisos claros, controles visibles, confirmación humana, registros de acciones y una experiencia donde el usuario pueda entender por qué el agente actuó de una forma determinada.
Un agente telefónico útil no tiene que reemplazar al usuario. Debe reducir pasos repetitivos, preparar decisiones y ejecutar acciones bien delimitadas cuando hay suficiente seguridad. En una tarea sencilla, puede organizar información y dejar un borrador listo. En una tarea sensible, debe pausar, resumir y pedir aprobación. Ese equilibrio es más lento de lanzar que una demostración, pero es el que evita que la automatización se convierta en una fuente de errores.
Por eso la pregunta por qué los agentes de IA avanzan más lento de lo esperado tiene una respuesta práctica: porque el valor real está en la fiabilidad, no solo en la sorpresa. El futuro del agente Android no dependerá únicamente de modelos más capaces. Dependerá de una capa de ejecución que haga que cada acción sea comprensible, autorizada, recuperable y proporcional al riesgo.
Fuentes consultadas: informes públicos recientes sobre el progreso más gradual de los agentes de IA en grandes compañías tecnológicas, junto con documentación y debates del sector sobre permisos móviles, ejecución local, interfaces de aplicaciones y controles de consentimiento. Estas fuentes se usan como contexto de industria, no como prueba de afiliación entre FoneClaw y otras empresas.