
Pourquoi les agents IA avancent plus lentement que prévu
Les agents IA impressionnent en démonstration, mais agir de façon fiable sur un téléphone Android demande permissions, interfaces d'app, validations humaines, reprise d'erreur et protection des données.
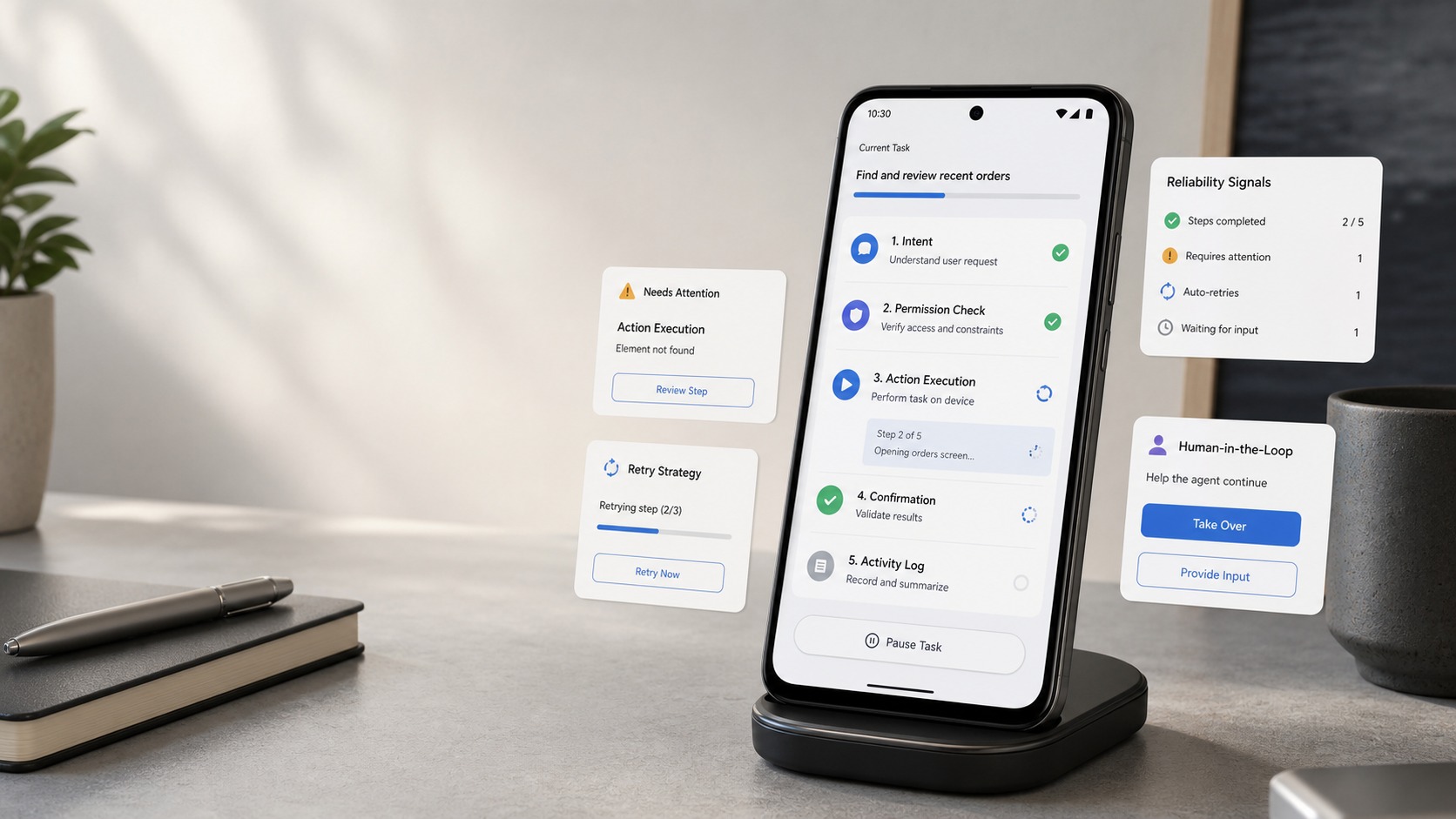
- Les agents IA avancent plus lentement que prévu parce qu'une démonstration réussie ne suffit pas à garantir une exécution fiable sur un vrai téléphone.
- Un agent IA sur smartphone a besoin d'une couche d'exécution capable de lire l'état des apps, d'obtenir les bonnes permissions, de confirmer les actions sensibles et de récupérer après une erreur.
- La validation humaine, les journaux d'action et les limites de confidentialité sont des fonctions de sécurité, pas des obstacles secondaires.
- FoneClaw aborde le téléphone comme un environnement contrôlé où l'agent doit expliquer, confirmer et tracer ce qu'il fait avant d'agir.
Les agents IA n'ont pas disparu, mais leur progression paraît plus lente parce que le passage de la conversation à l'action réelle est beaucoup plus exigeant qu'il n'y paraît. Un modèle peut comprendre une demande, produire un plan crédible et réussir une démo courte, puis échouer dès qu'il doit toucher plusieurs applications, interpréter un écran ambigu, respecter une permission Android ou attendre une confirmation humaine. La question n'est donc pas seulement pourquoi les agents IA avancent plus lentement que prévu, mais ce qu'il faut ajouter autour du modèle pour qu'il agisse sans mettre l'utilisateur en difficulté.
Sur un téléphone, la fiabilité se mesure à ce qui se passe après la bonne réponse. Si l'utilisateur demande de reporter un rendez-vous, l'agent doit trouver le bon calendrier, distinguer deux événements proches, vérifier les participants, préparer le message, obtenir l'accord final et laisser une trace compréhensible. Pour replacer ce type de scénario dans le fonctionnement général d'un agent mobile, notre guide sur ce que fait vraiment un agent IA sur téléphone aide à séparer l'assistance conversationnelle de l'action contrôlée.
Réponse courte
Les progrès semblent lents parce que les attentes publiques ont souvent confondu intelligence du modèle et fiabilité de l'exécution. L'intelligence permet de comprendre une demande, de raisonner sur une étape suivante ou de formuler une réponse. L'exécution fiable exige autre chose : connaître l'état exact du téléphone, agir dans une interface changeante, respecter les autorisations, éviter les doublons, détecter qu'une action n'a pas abouti et savoir revenir en arrière. Ces contraintes sont moins spectaculaires qu'une vidéo de démonstration, mais elles déterminent si l'utilisateur peut faire confiance à l'agent.
Les reportages publics sur les grands acteurs de l'IA ont décrit des progrès plus prudents qu'espéré pour les agents. Il faut lire ce signal avec mesure : il ne prouve pas que les agents échouent, il montre que les scénarios réels demandent des garde-fous. Un agent Android doit être capable de dire non, de demander plus de contexte et de suspendre une action lorsqu'il ne peut pas confirmer son résultat.
Pourquoi les démos trompent
Une bonne démo sélectionne souvent un chemin propre : une app déjà ouverte, des données préparées, peu de notifications et une demande sans ambiguïté. Dans cette situation, un agent peut paraître autonome parce que chaque étape attendue est visible et stable. Le quotidien d'un smartphone est différent. Une bannière peut masquer un bouton, une app peut changer de version, une session peut expirer, un champ peut contenir une ancienne valeur ou une permission peut bloquer l'étape suivante.
Le risque vient surtout des tâches multi-étapes. Réserver un trajet, répondre à un message puis créer un rappel demande de maintenir un objectif tout en vérifiant chaque résultat intermédiaire. Un agent qui clique au bon endroit neuf fois sur dix reste insuffisant si la dixième erreur envoie le mauvais message ou modifie la mauvaise réservation. Pour comprendre ce que les prochaines générations de modèles peuvent améliorer sans résoudre à elles seules toute l'exécution Android, l'analyse sur Gemini 3 et les agents Android prolonge ce point avec le bon niveau de prudence.
La démo met en avant la fluidité ; l'usage réel révèle les cas limites. C'est pourquoi la fiabilité des agents IA ne peut pas être jugée seulement sur la qualité linguistique ou la vitesse de raisonnement. Elle dépend de la capacité à reconnaître l'incertitude et à ralentir volontairement lorsque le coût d'une erreur augmente.
La couche d'exécution manquante
Un agent IA sur smartphone a besoin d'une couche d'exécution entre le modèle et les applications. Cette couche traduit l'intention en actions contrôlables : lire l'écran, appeler une interface d'application quand elle existe, vérifier les permissions, comparer l'état avant et après, puis conserver un chemin de récupération. Sans cette couche, l'agent ressemble à un utilisateur pressé qui touche l'écran sans mémoire fiable de ce qu'il vient de modifier.
Les interfaces prévues pour être appelées par une machine sont particulièrement importantes. Elles évitent de dépendre uniquement de la reconnaissance visuelle ou de boutons qui changent de place. Quand une app expose des actions structurées, l'agent peut demander une opération précise, recevoir un résultat plus clair et limiter les erreurs d'interprétation. Notre article sur les interfaces d'applications utilisables par les agents IA explique pourquoi cette architecture est plus solide que le simple pilotage d'écran.
La récupération compte autant que l'action. Si un paiement échoue, si une pièce jointe ne part pas ou si un contact n'est pas le bon, l'agent doit pouvoir arrêter le flux, expliquer l'écart et proposer une correction. Une couche d'exécution sérieuse conserve donc des états, pas seulement une suite de gestes.
Le rôle de la validation humaine
La validation humaine n'est pas un aveu de faiblesse. Elle définit les moments où l'utilisateur doit reprendre la décision : envoyer un message, supprimer un fichier, confirmer un achat, modifier un paramètre de confidentialité ou partager une donnée personnelle. Plus l'action est irréversible ou sensible, plus l'agent doit ralentir et présenter ce qu'il s'apprête à faire dans un langage simple.
Un bon système distingue les tâches à faible risque des décisions qui exigent un consentement explicite. Classer des notifications ou préparer un brouillon peut être automatisé avec une surveillance légère. Envoyer ce brouillon, accepter une invitation ou changer une option de sécurité demande une confirmation nette. Pour voir comment un centre de contrôle peut organiser ces validations, l'article sur le centre de contrôle des agents mobiles montre pourquoi l'utilisateur doit garder une vue claire des actions en attente.
Les journaux d'action sont l'autre moitié de la confiance. Après coup, l'utilisateur doit pouvoir voir ce qui a été demandé, ce que l'agent a compris, quelle app a été touchée et quelle confirmation a été donnée. Sans historique lisible, il devient impossible de distinguer une erreur de modèle, une erreur d'interface ou une décision validée trop vite.
Pourquoi le téléphone complique tout
Un chatbot travaille dans une fenêtre relativement stable. Un téléphone, lui, mélange notifications, permissions, comptes, apps tierces, connexions réseau et données locales. Deux utilisateurs peuvent formuler la même demande et présenter des environnements entièrement différents. L'un a deux calendriers synchronisés, l'autre utilise une app de messagerie professionnelle, un troisième a refusé l'accès aux contacts. L'agent doit donc raisonner avec un contexte incomplet et parfois contradictoire.
Android ajoute une diversité utile mais exigeante : versions du système, surcouches constructeur, paramètres d'accessibilité, langues de l'interface, restrictions de batterie et écrans d'autorisation. Pour un agent Android, cliquer sur un bouton ne suffit pas ; il faut savoir si le bouton correspond bien à l'action voulue dans ce contexte précis. Un changement de libellé ou un écran de consentement inattendu doit déclencher une vérification, pas une improvisation risquée.
Le téléphone contient aussi des signaux privés. Les messages, photos, contacts, historiques d'appel et emplacements récents peuvent aider l'agent, mais ils augmentent la responsabilité du système. La bonne conception consiste à donner juste assez de contexte pour accomplir la tâche, avec une explication claire de ce qui est consulté et pourquoi.
Local ou cloud : le vrai compromis
Le raisonnement dans le cloud peut offrir plus de puissance, une meilleure compréhension de demandes complexes et des mises à jour rapides du modèle. L'exécution locale peut réduire l'exposition des données, accéder plus directement à certains états du téléphone et continuer à fonctionner dans des conditions réseau limitées. Le choix n'est pas idéologique : une architecture fiable combine souvent les deux selon la sensibilité de la tâche.
Par exemple, l'analyse générale d'un itinéraire ou la rédaction d'un message peut bénéficier d'un modèle distant, tandis que la lecture d'une notification privée, la confirmation d'une permission ou l'application d'un réglage doivent rester étroitement contrôlées côté appareil. Pour comparer ces compromis sans réduire le sujet à une opposition simple, le guide agent téléphone local ou cloud détaille les conséquences sur la confidentialité, la latence et la fiabilité.
Le point décisif est la limite de circulation des données. Un agent doit indiquer quelles informations quittent l'appareil, lesquelles restent locales et quelles actions peuvent être effectuées sans transfert inutile. La confiance vient moins d'une promesse générale que d'une séparation visible entre raisonnement, contexte privé et exécution.
Ce que les utilisateurs doivent attendre
Avant de confier des tâches réelles à un agent, l'utilisateur devrait chercher des critères concrets. L'agent explique-t-il son prochain geste avant une action sensible ? Peut-il montrer l'app ou l'état qu'il va modifier ? Demande-t-il une validation pour les envois, achats et suppressions ? Garde-t-il un historique compréhensible ? Sait-il s'arrêter lorsqu'il n'est pas certain ? Ces questions valent plus qu'une promesse d'autonomie totale.
Un autre critère est la granularité des permissions. Autoriser un agent à préparer un brouillon n'est pas la même chose que l'autoriser à l'envoyer. Lire un calendrier pour trouver un créneau n'implique pas de pouvoir inviter des participants. Une bonne expérience propose des niveaux d'accès distincts, révocables et expliqués au moment où ils sont nécessaires.
La vitesse ne doit pas être le premier indicateur de qualité. Pour une action sans conséquence, l'agent peut aller vite. Pour une décision coûteuse, il doit ralentir, résumer et demander confirmation. Cette variation de rythme est un signe de maturité : l'agent adapte son comportement au risque au lieu de traiter toutes les tâches comme une simple conversation.
Ce que cela signifie pour FoneClaw
Pour FoneClaw, la leçon est claire : un agent de téléphone ne doit pas être présenté comme une magie qui remplace l'utilisateur partout. Il doit être conçu comme un assistant d'exécution contrôlé, capable de comprendre une intention, de préparer une action, de montrer ses hypothèses et de demander l'accord au bon moment. Cette approche évite de confondre ambition technologique et promesse irréaliste.
FoneClaw ne dépend pas d'une affiliation avec Meta, Google, Android, Gemini, OpenAI ou Apple pour expliquer ce principe. Le sujet est plus fondamental : toute solution qui veut agir sur un smartphone doit traiter les permissions, l'état des applications, la confidentialité, les confirmations et la reprise d'erreur comme des composants centraux. Le modèle est important, mais il n'est qu'une partie du système.
Les agents IA paraissent plus lents que prévu parce que le marché apprend à mesurer autre chose que l'effet de démonstration. Sur téléphone, la vraie avancée sera visible quand l'utilisateur pourra déléguer une tâche utile, comprendre ce qui va se passer, valider les étapes sensibles et corriger facilement le résultat. C'est ce niveau de contrôle qui transformera l'agent IA sur smartphone en outil quotidien fiable.
Sources consultées : reportages publics sur la progression plus prudente des agents IA dans l'industrie, documentation générale sur les permissions Android et analyses de conception sur les interfaces d'applications pilotables par des agents.